


Author Classifier using BERT
Introduction
The Author Classifier project aims to classify authors based on the text they have written using advanced natural language processing techniques. Leveraging concepts from the Information Retrieval course, we built a dataset comprising a minimum of 35 books for each of the 10 selected authors. The dataset underwent preprocessing, including tokenization and stop-word removal, implemented through two different approaches to explore the impact on model performance.
View the project on GitHub to explore its codebase and contributions
Methodology
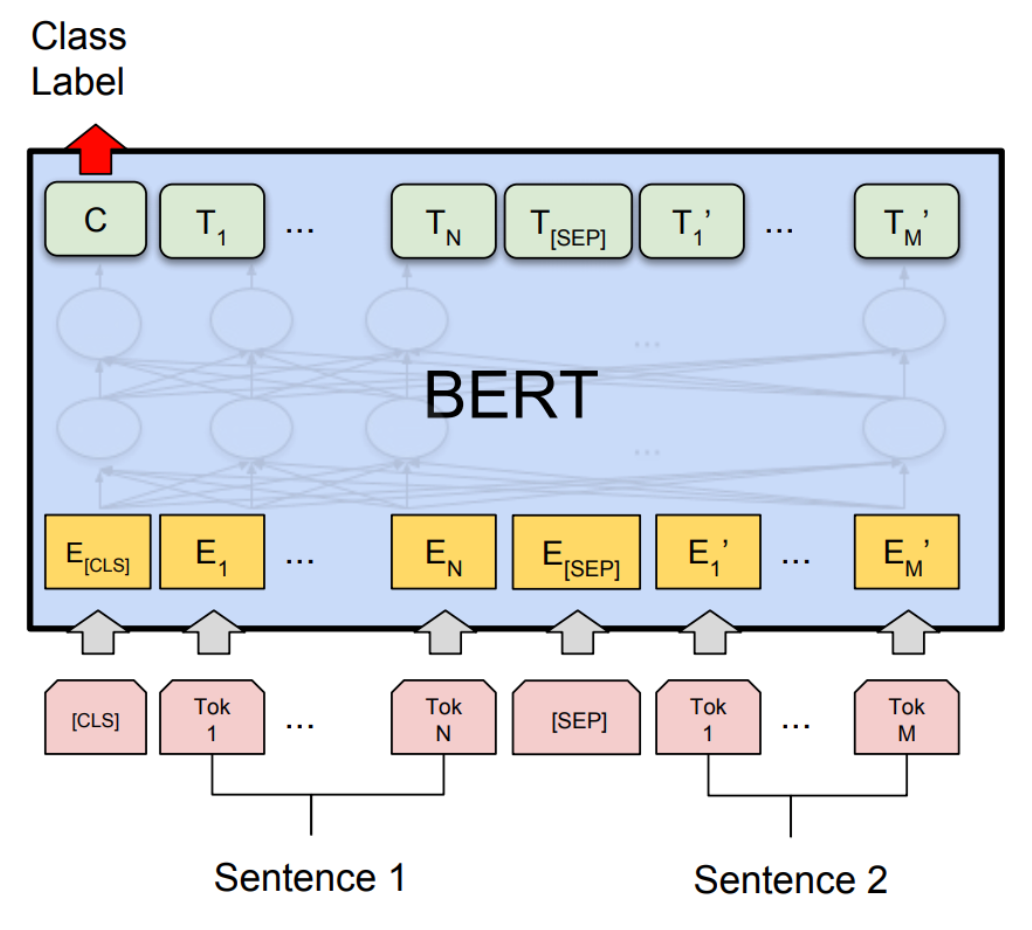
We employed BERT (Bidirectional Encoder Representations from Transformers) from the Hugging Face library to tokenize and embed the preprocessed text data. Our model architecture includes a customized fine-tuning of BERT, followed by a dense layer, as our task involved 10 distinct author classes. For loss calculation, we utilized categorical cross-entropy. To optimize training efficiency, we experimented with the inclusion of dropout layers and tested various hyperparameters such as document max_len and learning rate scheduling.
Results
Through rigorous experimentation, we identified optimal hyperparameters that enabled rapid training convergence within a few epochs while achieving high accuracy. Our model consistently outperformed others in the course, attaining a perfect score of 10/10 in evaluation. This project not only demonstrates the efficacy of BERT-based models for author classification tasks but also highlights the importance of meticulous hyperparameter tuning in achieving superior performance.
Usage
- Dataset Creation:
- Assemble a dataset comprising a minimum of 35 books for each of the 10 selected authors.
- Preprocess the dataset, including tokenization and stop-word removal, using two different approaches.
- Model Training:
- Tokenize and embed the preprocessed text data using BERT from the Hugging Face library.
- Customize and fine-tune the BERT model with a dense layer for author classification.
- Experiment with dropout layers and various hyperparameters to optimize training efficiency and accuracy.
- Evaluation:
- Evaluate the trained model’s performance using metrics such as accuracy and loss.
- Compare the model’s performance with different preprocessing approaches and hyperparameter settings.
- Deployment:
- Deploy the trained model for real-world author classification tasks, ensuring seamless integration with relevant applications or systems.
Project Report
A comprehensive report detailing every aspect of our project, including methodology, experimental setup, results, and analysis, has been meticulously prepared. This report encapsulates the journey of our project from dataset creation and preprocessing to model development, training, and evaluation. It provides an in-depth exploration of the various preprocessing approaches employed, the fine-tuning process of the BERT model, and the extensive hyperparameter tuning conducted to optimize performance. Furthermore, the report showcases the results obtained, including accuracy metrics, loss values, and comparisons between different experimental setups. Through this detailed report, we aim to provide transparency and insight into our project’s methodologies and findings, ensuring a thorough understanding of our approach and outcome